분석을 위해 머신러닝 분류기 모델을 생성합니다. 참조 논문과 동일하게 Accuracy, F1 Score, ROC_AUC 성능평가를 통해 XGBoost가 적합한 모델임을 확인했습니다. 모델을 생성하고, SHAP 분석을 통해 각 요인(독립변수)의 영향력을 확인합니다.
분석 후 참조 논문과 같이 신규 음식점에 대한 장단기 운영 예측을 수행하려 하였으나 음식점의 폐업에는 '양도양수'가 빈번하게 일어나고 공공데이터만으로는 음식점의 폐업 사유가 운영 부진으로 인한 폐업인지 다른 사람에게 소유를 넘기기 위한 폐업인지 알 수 없기 때문에 장단기의 예측이 음식점 운영의 좋고 나쁨과 결부되기엔 적절하지 않다고 판단하여 분석 방법과 결과에 대해서만 설명합니다.
설명의 순서는 다음과 같습니다.
[모델: XGBoost]
1. GridSearchCV를 통한 최적의 하이퍼파라미터 탐색
2. 모델 생성
3. SHAP 분석(Importance, Summary plot)
4. SHAP 분석(Dpendence plot)
5. 결론
1. GridSearchCV를 통한 최적의 하이퍼파라미터 탐색
- 참조 논문에서 제안한 내용을 기준으로 다음과 같은 범위를 탐색하였습니다.
- 장단기의 데이터가 동일하게 2,000개이므로 Cost sensitive learing weights는 설정하지 않습니다.
[Model Hyperparameter Search Space]
| 하이퍼파라미터 | 범위 |
| n_estimators | 200, 400, 600 |
| max_depth | 5, 7, 9 |
| learning_rate | 0.07, 0.08, 0.09, 0.1 |
| subsample | 0.4, 0.5, 0.6 |
| colsample_bytree | 0.8, 0.9, 1.0 |
| max_bin | 33, 25 |
| tree_method | hist, approx |
[Best Hyperparameter]
| 하이퍼파라미터 | 값 |
| n_estimators | 400 |
| max_depth | 9 |
| learning_rate | 0.09 |
| subsample | 0.5 |
| colsample_bytree | 1.0 |
| max_bin | 33 |
| tree_method | approx |
2. 모델생성
- K-Fold 교차검증을 5분할씩 10번 수행하여 모델을 생성하고, 총 50개의 모델의 Accuracy, F1 Score, ROC_AUC를 평균하여 모델의 성능을 평가합니다.
[ k-Fold Cross-Validation]
| 반복횟수 | 분할 | 데이터 섞음 | 총 모델 수 |
| 10 | 5 | ○ | 50 |
[Test Score Mean(Std)]
| Accuracy | F1 Score | ROC_AUC | |
| 평균 | 0.654 | 0.653 | 0.716 |
| 표준편차 | 0.013 | 0.016 | 0.017 |
3. SHAP 분석(Importance, Summary plot)
- 50개의 모델에 대한 SHAP value의 평균을 분석 데이터로 사용합니다.
- Importance plot: 절대값, Summary plot: 양수/음수 산점도
- SHAP value는 양수일 경우 양의 영향력을, 음수일 경우 음의 영향력을 가집니다.
(양의 값: 5년 이상 운영으로 분류될 확률이 높음)
- 변수의 값이 클수록 붉게, 작을수록 파랗게 표시됩니다.
1) 참조 논문 결과: 2023년 8월 1일 기준 (5년 이상 영업 폐업 / 6개월 미만 영업 폐업)
- 참조 논문의 결과를 '이전 결과'라고 한다면, 이전 결과에서는 1000m 내 60대 생활인구비와 시설규모가 가장 큰 영향력을 행사함을 확인할 수 있습니다. 두 요인 모두 값이 클수록 5년 이상 운영으로 분류될 확률이 높아집니다.
- 세번 째로 큰 영향력을 행사는 요인은 300m 내 유사업태 수입니다. 위 두 경우와 반대로 값이 클수록 6개월 미만 영업으로 분류 될 확률을 높입니다.
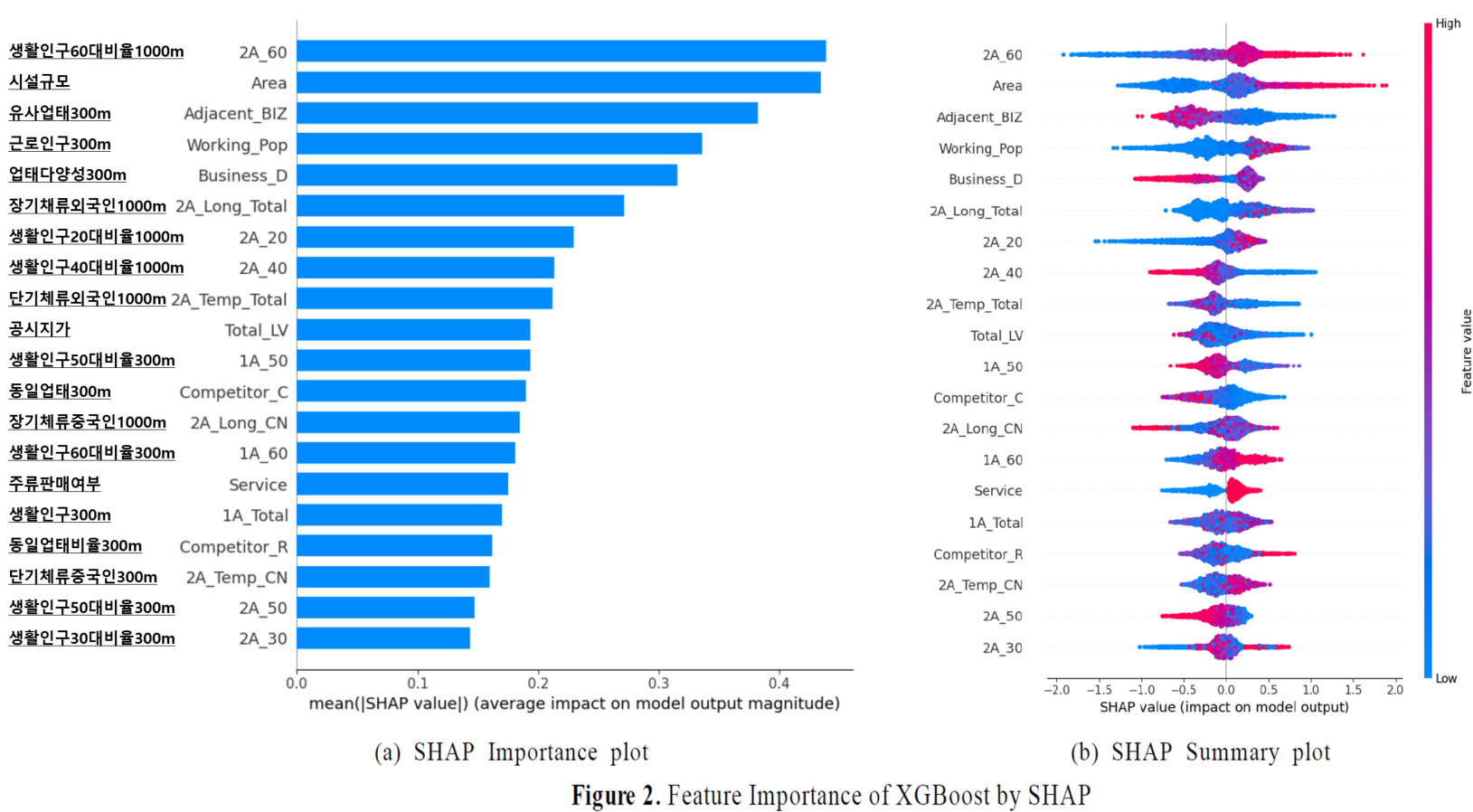
2) 2024년 11월 5일 기준 (5년 이상 영업중 / 1년 미만 영업 폐업)
- 이전 결과와 동일하게 1000m 내 60대 생활인구비와 시설규모가 가장 큰 영향력을 행사함을 확인할 수 있었습니다. 그리고 시설규모의 영향력이 다른 요인에 비해서 상대적으로 크고, 얇은 꼬리가 없고, 이전 결과에 비해 더 높은 영향력에 높은 값의 분포가 많은 특징을 보입니다. 시설규모가 고르게 분포하고, 큰 음식점이 많은 것으로 확인됩니다.
- 300m 내 업태의 다양성의 경우 이전 결과에 비해 반대 방향으로 돌아서는 양상을 보입니다.

- 가장 영향력이 큰 시설규모를 제외할 경우 모델의 성능과 영향력이 어떻게 바뀌는지 확인해보겠습니다.
- 전체적으로 모델의 성능이 떨어지는 것을 확인할 수 있고, 1000m 내 60대 생활인구비가 여전히 영향력이 큰 것으로 보이나 이전 결과와 달랐던 300m 내 업태의 다양성이 가장 큰 영향력을 행사하는 것으로 확인됩니다.
[Test Score Mean(Std)]
| Accuracy | F1 Score | ROC_AUC | |
| 평균 | 0.596(0.058) | 0.608(0.045) | 0.645(0.071) |

4. SHAP 분석(Dpendence plot)
- 요인의 영향력과 상호작용을 같이 나타낸 그래프입니다. 개별 변수에 대해 자세한 정보를 확인할 수 있습니다.
1) 1000m 내 60대 생활인구 비율
- 60대 생활인구 비율이 높아질 수록 장기 운영으로 분류될 확률이 높아집니다. 10% 이상이 될 경우 영향력이 퍼지는 경향을 보입니다.
- 업태의 다양성은 고르게 분포하여 60대 비율과 상호작용이 없는 것을 확인할 수 있습니다.

2) 300m 내 업태 다양성
- 다양한 유사업태의 음식점이 모여 있는 경우 장기 운영으로 분류될 확률이 높아질 수 있지만 반대의 경우가 아주 없는 것은 아닌 것으로 보입니다. SHAP value의 0을 기준으로 우측으로 갈 수록 분포가 많아 지는 것을 확인할 수 있습니다.
- 단기체류 외국인은 업태가 다양한 쪽으로 높은 분포를 보입니다.

5. 결론
1) 장단기 운영 여부를 분류하는 목적은 음식점의 생존에 대한 문제임에 따라 단기 표본은 경영의 어려움으로 폐업하는 음식점 을 표본으로 추출해야 합니다. 하지만 공공데이터를 통해서는 구분이 안되는 치명적인 문제가 있었습니다. 또한 가장 영향력이 큰 시설규모의 경우 값이 커지면 음식점의 가치가 같이 커짐에 따라 양도양수의 빈도가 낮을 것으로 자연스럽게 예상할 수 있습니다. (글쓴이의 경험과 프렌차이즈 관리자의 인터뷰를 통해 단기간 운영한 잘 되는 음식점을 '양도양수' 하는 경우가 비번함을 알 수 있었음)
2) 시설규모를 제외하면 60대 생활인구 비율과 업태의 다양성이 뚜렷한 영향력을 보이고 있습니다.
3) 특히 노인 인구에 대해서는 통계청 「2024 고령자통계」의 내용을 미루어 볼 때 ‘24년 65세 이상 고령인구는 전체 인구의 19.2%로, 향후 계속 증가하여 ’25년에 20%, ‘36년에 30%, ’50년에 40%로 전망 되는 가운데 '23년 가구주 65세 이상 고령자 가구의 순자산액은 4억 5,540만 원(전년 대비 176만원 증가)으로 상대적 빈곤율 또한 증가하고 있지만 소득이 보장된 인구가 많은 것을 확인할 수 있습니다.
4) 또한 2022년 65세 이상 고용률은 36.2%로 지난 10년간 6.1%p 상승하였고, ’21년 OECD 회원국 중 65세 이상 고용률은 우리 나라가 가장 높은 수준입니다.
5) 따라서 단기 영업 후 폐업 사유를 확인할 수 없는 문제로 인해 직접적으로 본 모델을 기용하기는 어렵다고 생각됩니다. 다만 거시적인 측면에서 높은 60대 생활인구와 업태의 다양성이 장기적으로 음식점을 운영하는데 유리하다고 판단됩니다.
'XGBoost' 카테고리의 다른 글
| 서울시 음식점의 장단기 운영 예측 #2 [데이터 수집] (0) | 2024.11.22 |
|---|---|
| 서울시 음식점의 장단기 운영 예측 #1 [논문과 목표] (2) | 2024.11.22 |

